Large language models (LLMs) undoubtedly demonstrate impressive results in writing code, including code that requires fairly complex reasoning. That’s why you so often hear about “the extinction of the programmer profession.” I would say that the programmer’s profession will change significantly, but we’re no strangers to such changes. Routine tasks get automated, and commonly used procedures and algorithms are packaged into libraries. Yet the main task remains: understanding what the user wants, what problems they wish to solve, and formulating these requirements in a clear and unambiguous way.
Essentially, such a formal description is itself a form of top-level code. Most of the time, it can’t be executed by a machine directly, since it uses concepts the machine is unfamiliar with. Therefore, the programmer works top-down through layers of abstraction, explaining these concepts to the machine in simpler terms, using libraries and the runtime environment.
Thus, a programmer must:
- Find the tools and libraries best suited to solving the user’s problem.
- Learn how these tools and libraries describe the domain they work with, and which terms and abstractions they use.
- Reformulate the user’s problem in these terms.
- Write out this reformulation as correct program code.
It’s the fourth step that tends to get the most attention when it comes to applying LLMs. But in fact, this is the easiest stage, and it corresponds to a junior programmer’s responsibilities. System architects and senior programmers spend most of their time on the first three steps. And here, LLMs can (and already do) provide significant help, allowing you to quickly start new projects in unfamiliar domains and to implement unconventional features.
I want to share the experience of one such project that I’ve been working on for the past six months, using various AI models from OpenAI.
For quite a while now, I’ve been developing my own decentralized social network called Moera. And the time came when the network needed a search server—one that would index content, enable searching by various criteria, and provide “what to read next” recommendations. The hardest part was the recommendation system, and that’s the question I brought to GPT-4o:

The LLM produced the standard ideas about representing social connections as a graph and searching through it with algorithms. So, I had to clarify that I was talking about very large graphs.

Database with Graph Capabilities? That was the first time I’d heard of such a thing. What kind of features do they have?

It turned out to be exactly what I needed! I immediately went to Amazon and ordered a book on graph databases.
But recommendations based on social connections are only part of the picture. What about content-based recommendations? For this, I turned to Deep Research—the best and most indispensable tool for exploring new areas. Deep Research produced an excellent overview based on dozens of sources. But I decided not to go in that direction for now, as it’s a huge undertaking. A simpler option is to classify texts according to a standard set of topics. GPT-4o gave me several affordable options for implementing this:

As for full-text search, I had some basic knowledge in this area, but it was a bit outdated. GPT-4o helped me learn about the benefits of Elasticsearch:

As a result, I chose OpenSearch—an open-source alternative to Elasticsearch. I also asked the LLM to compare full-text search in Neo4j with OpenSearch and concluded that using Neo4j for the graph and OpenSearch for search was the best idea. The only thing left was to make sure OpenSearch had all the features I needed and to decide what data from Neo4j should be duplicated in OpenSearch. Here, the “thinking” models o3 and o4-mini were most effective.
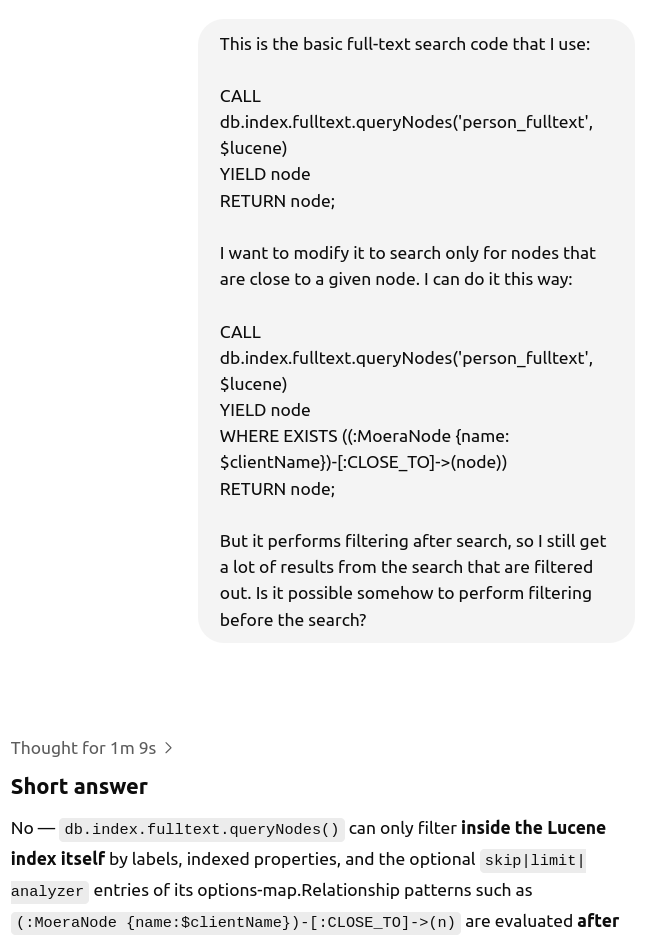
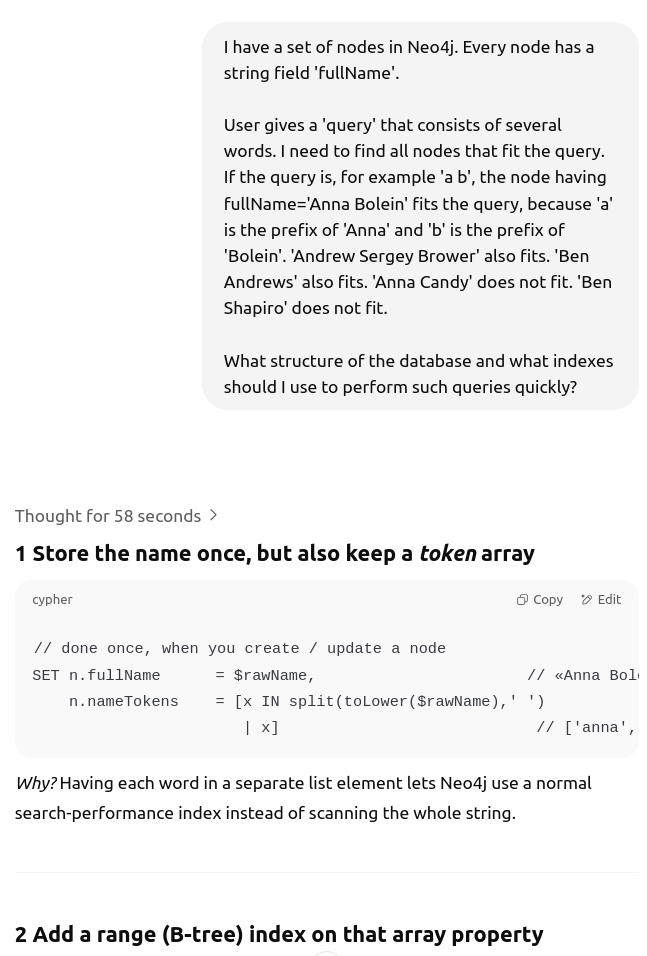


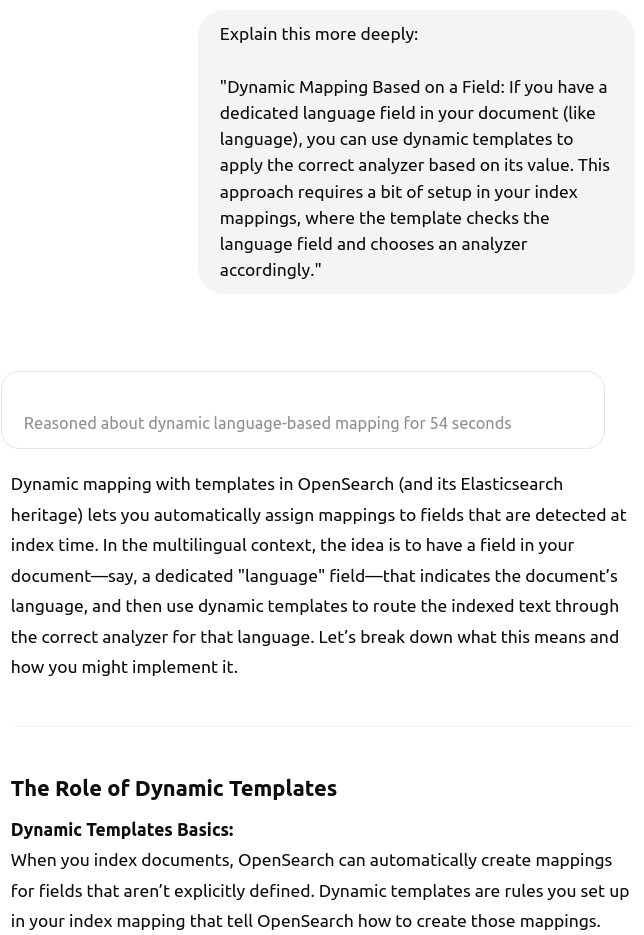

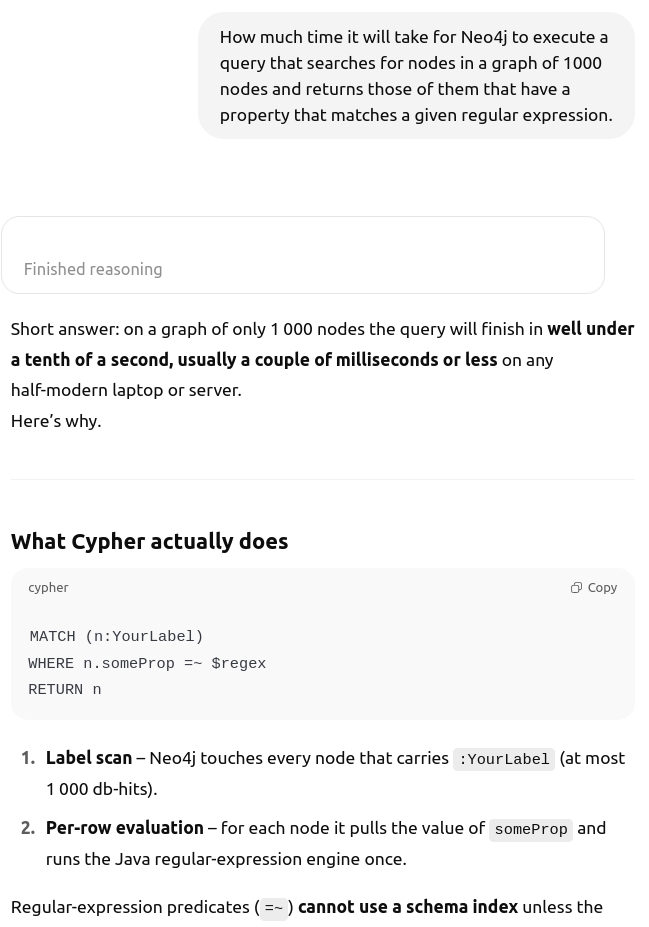
During implementation, I often had questions about the Cypher query language for Node4j and the OpenSearch query language. All of these were quickly resolved with the help of the LLM—it provided code examples and clarified confusing points. It was also a big help during deployment, explaining how AWS pricing works and what all those abbreviations mean.
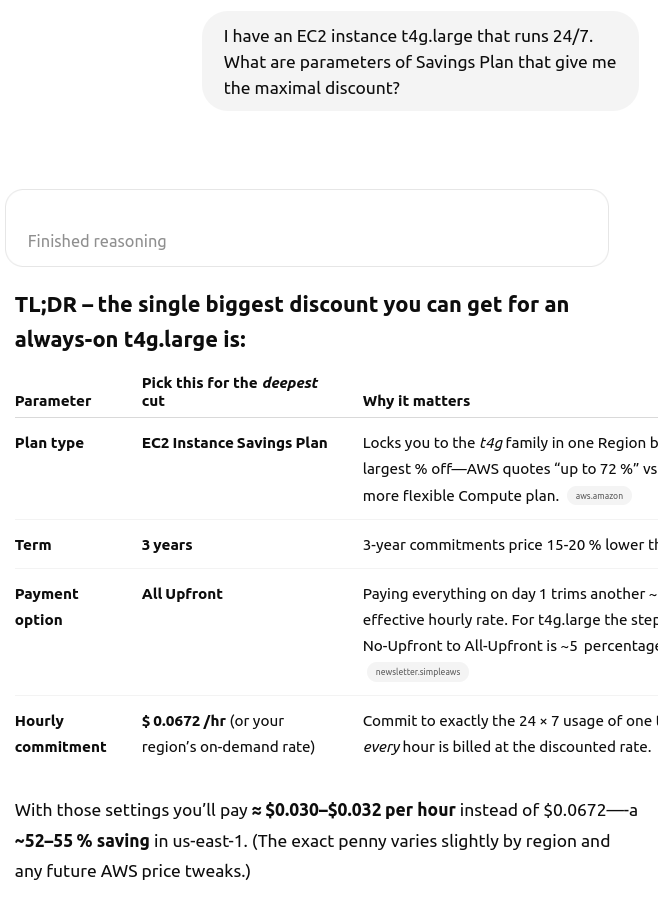
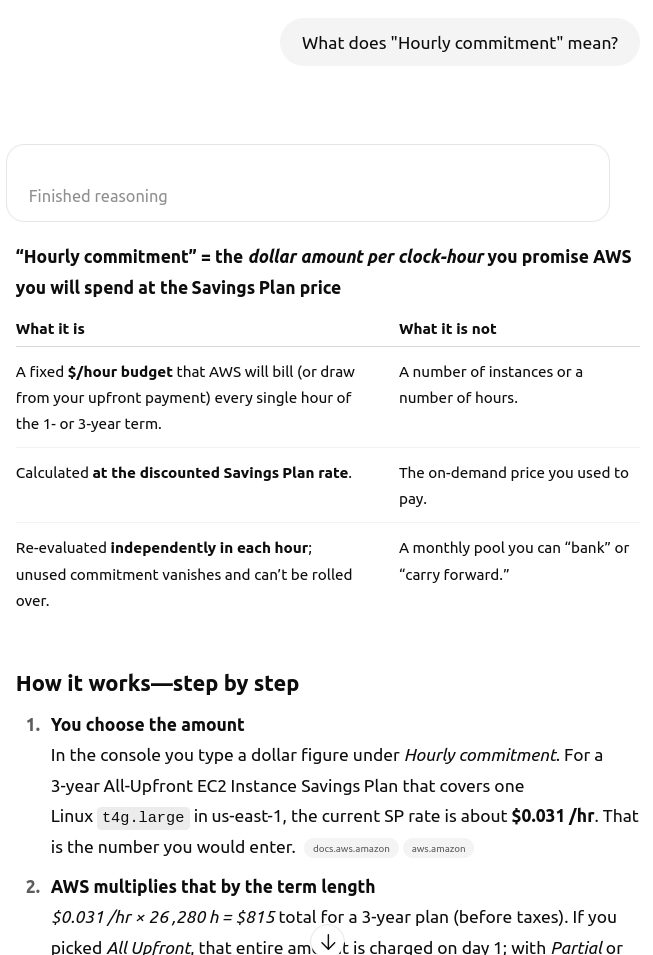


As a result, I managed to launch the first version of the search server in just two weeks, and a version with full-text search in six weeks.
There were two more points in the development process that are worth mentioning.
The first was related to calculating the “closeness” of friends based on the number of likes and comments they gave each other. Each like or comment added “closeness points,” but their effect needed to decrease as the number of likes grew. In other words, I needed a monotonically increasing function that maps any non-negative number to the range [0, 1), growing rapidly at first and asymptotically approaching 1. I asked o4-mini to give me examples of such functions:

In the end, I chose the hyperbolic tangent.
The second moment was when I decided to see if I could quickly and inexpensively implement text recognition in images. Let's ask Deep Research: https://chatgpt.com/s/dr_684f96703e048191966f340a797ed2a4
I discovered a fantastic and almost free service—OCR.space. GPT-o3 helped me quickly set up an API implementation:

Sometimes, however, when recognizing text in unfamiliar languages, you get gibberish. Deep Research suggested using LanguageTool to filter the results: https://chatgpt.com/s/dr_684f97c786348191ae0af302d283c5fb Voilà, everything works great!
So, what can be said in conclusion? LLM is an excellent expert friend on any topic, saving weeks of research, trial, and error. It allowed me to quickly accomplish things that I wouldn’t have even attempted otherwise—given how limited time and resources are. It seems that our idea of what tasks can be solved by a single person or a small team is already due for a serious update.
Comments (1)
Много буков, конечно, но очень хорошо все описано, дочел.